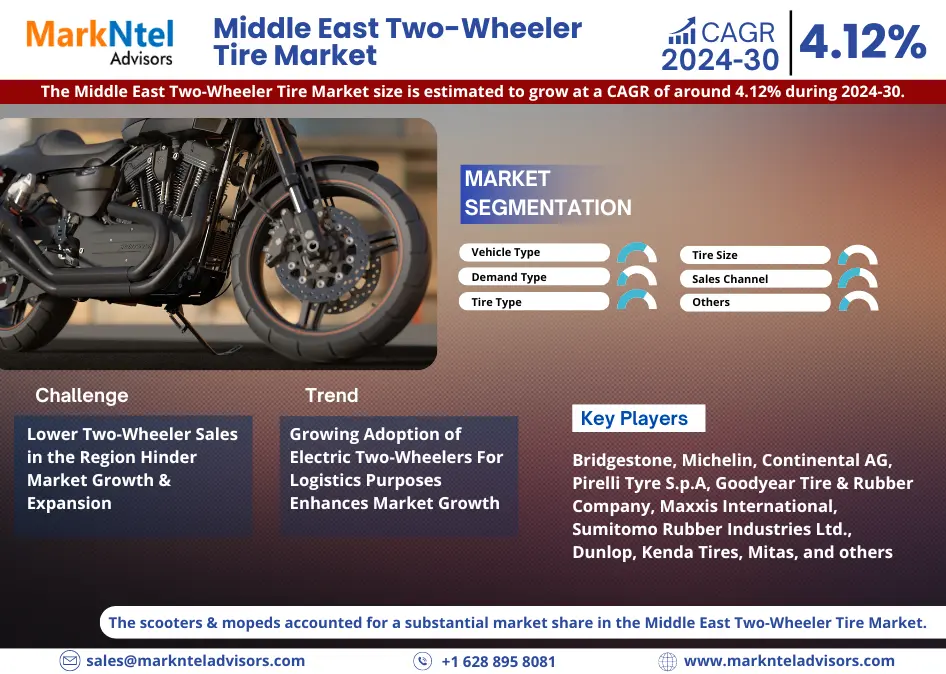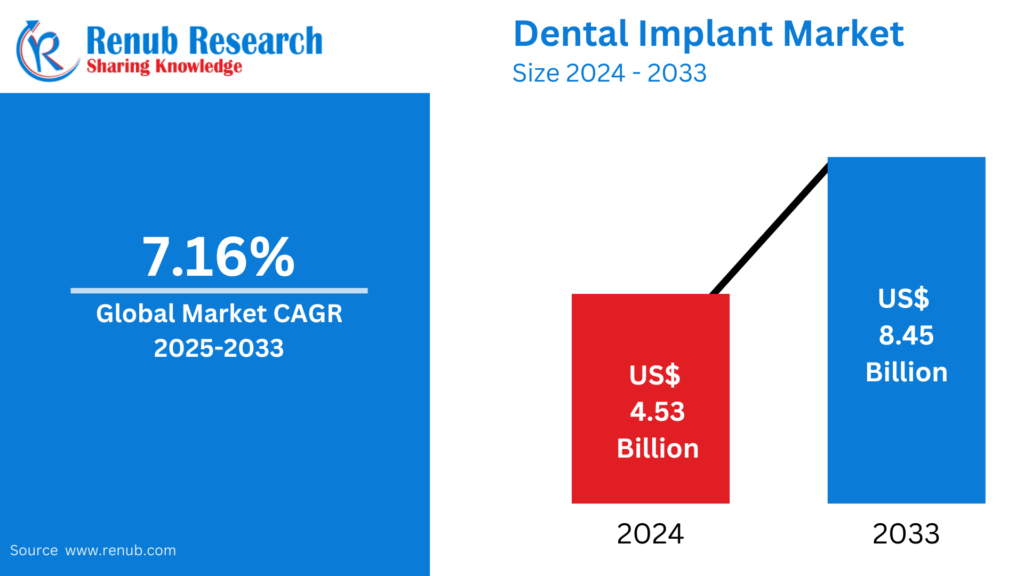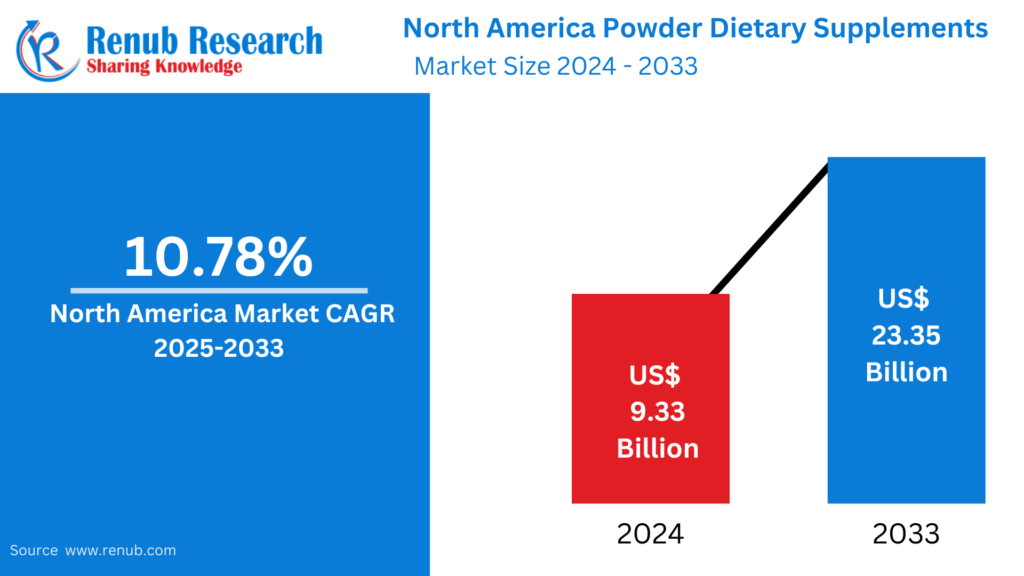





































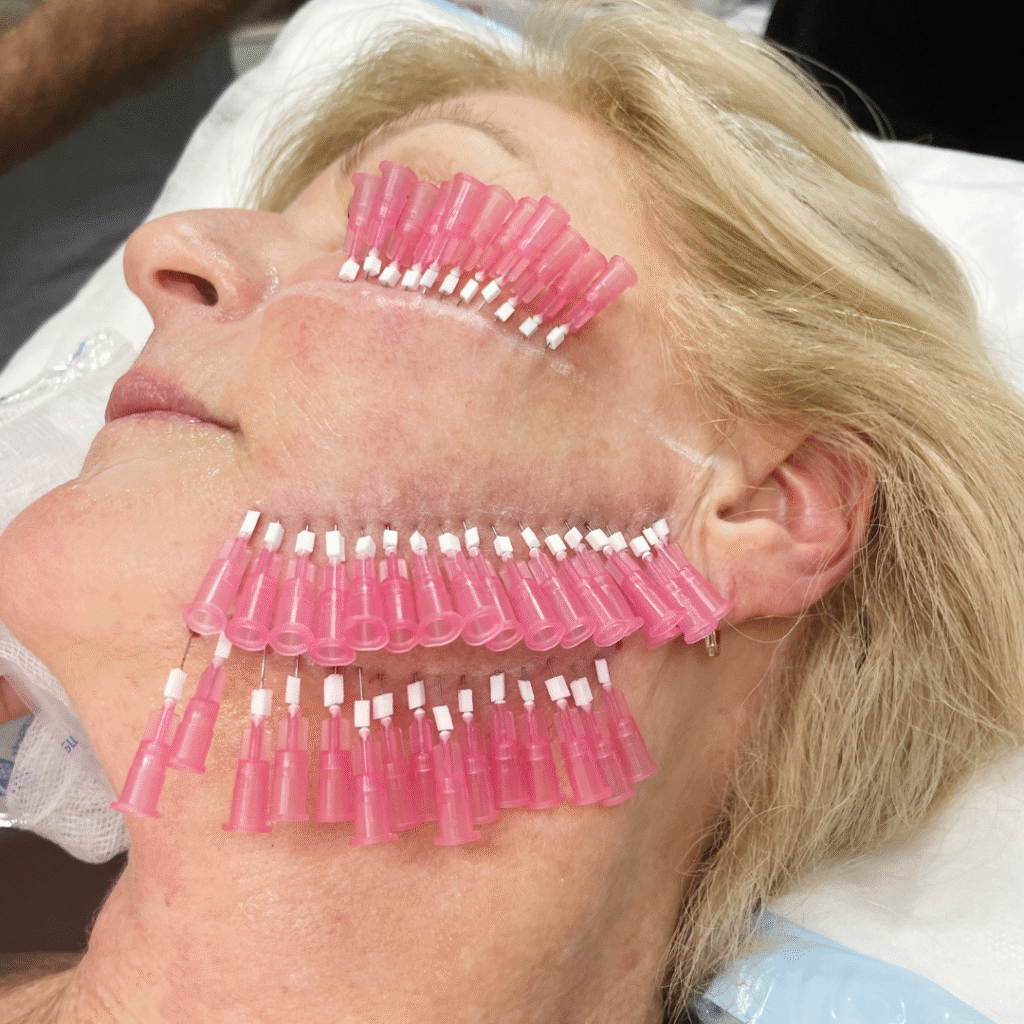








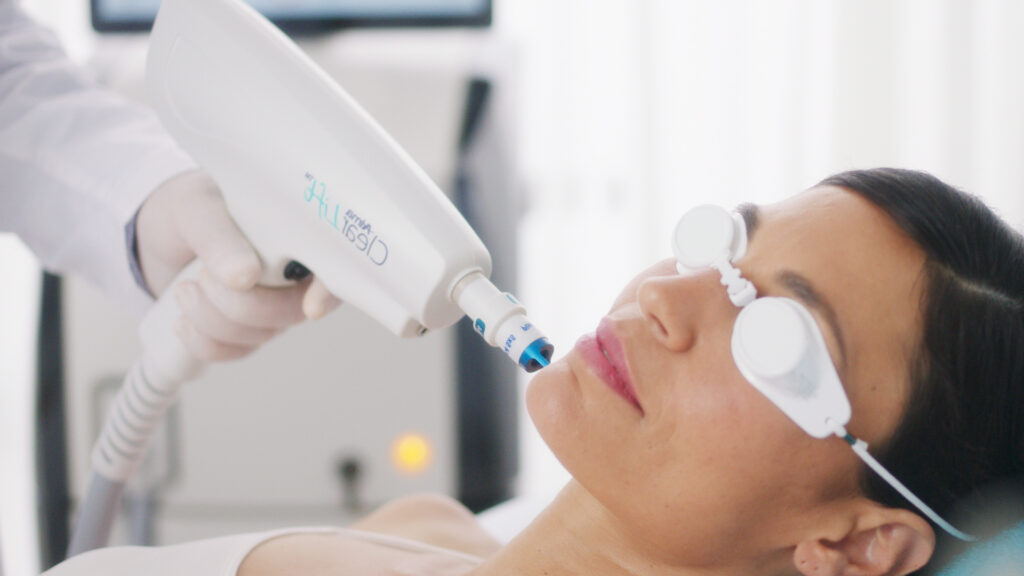


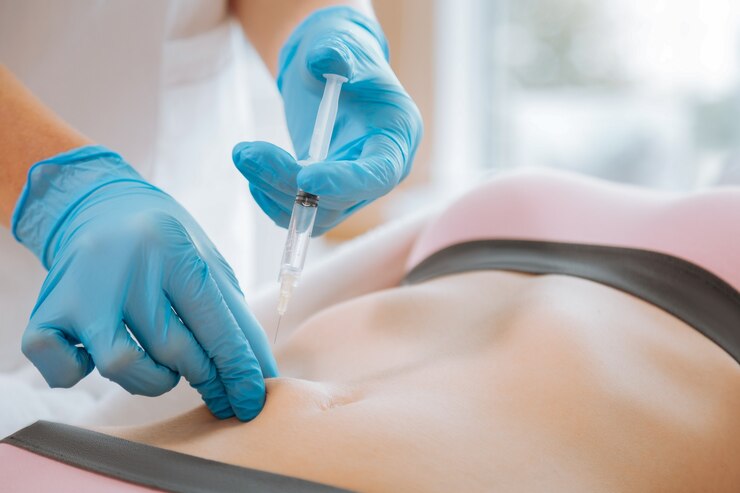







































































































































































































































































































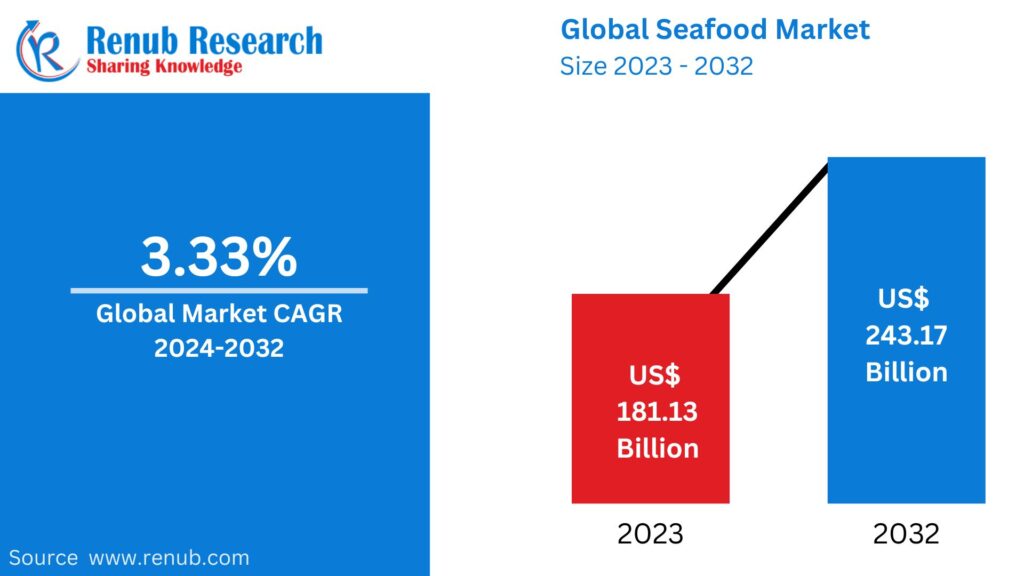









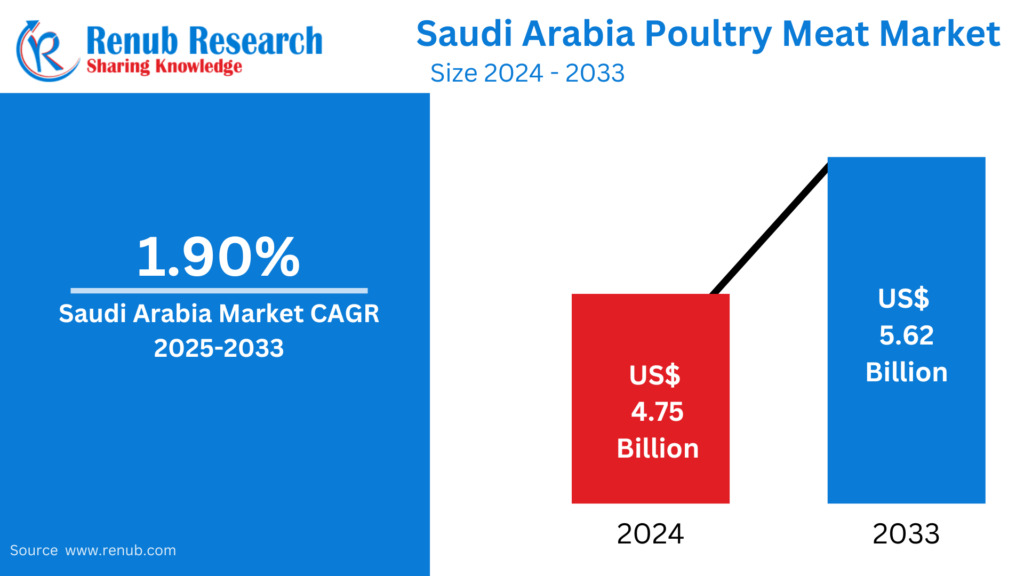











































































































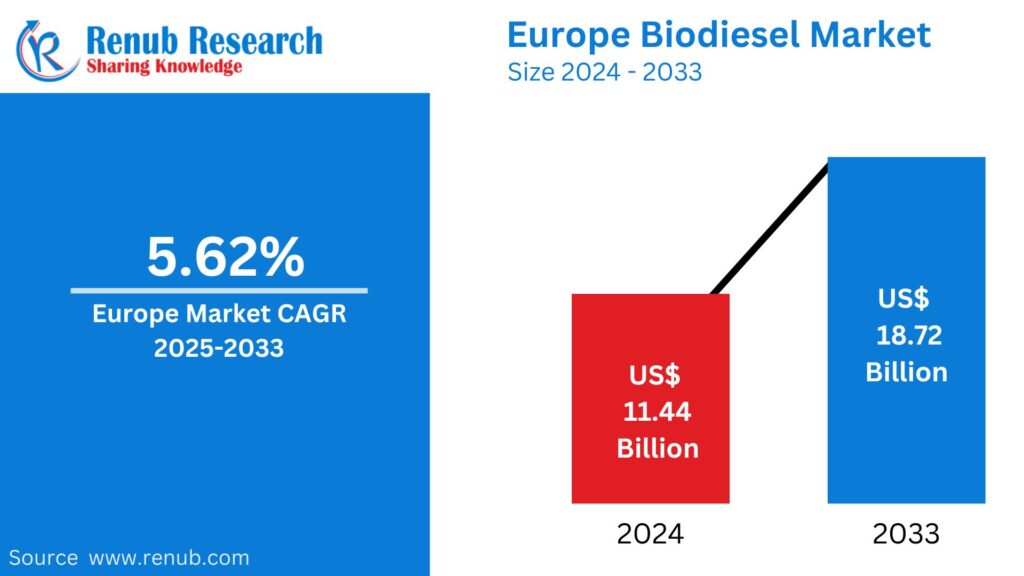



























































































































































































































































































































































































































































































































































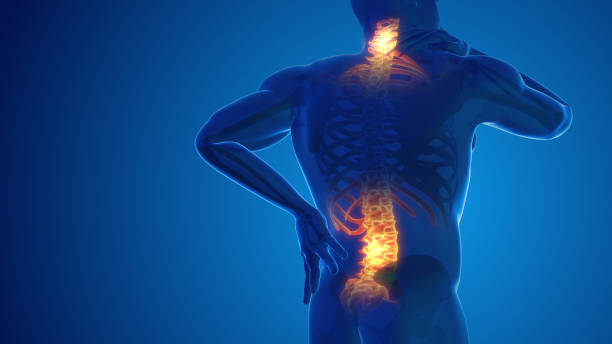





































































































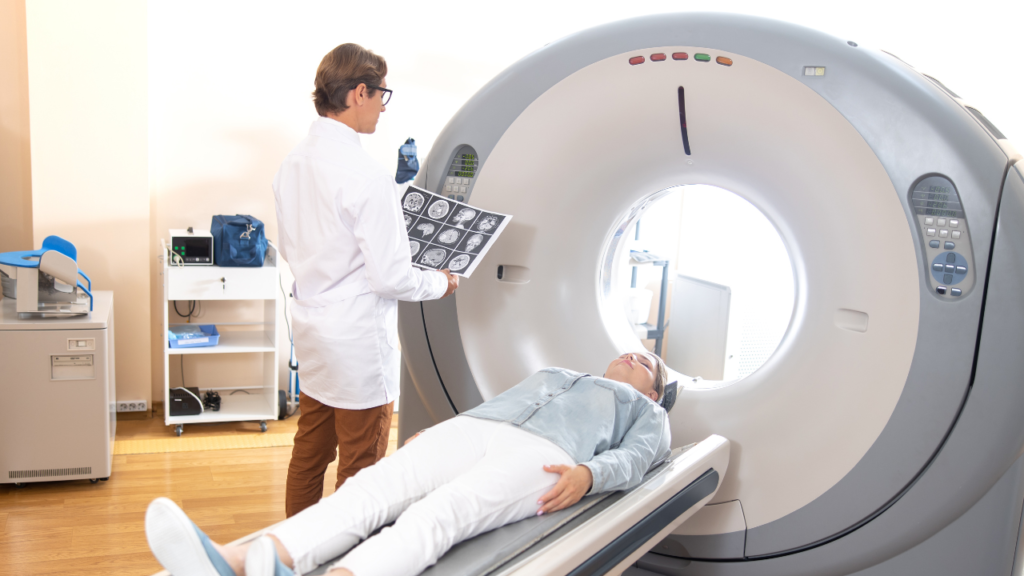



























































































































































































































































































































































































































































































































































































































 01
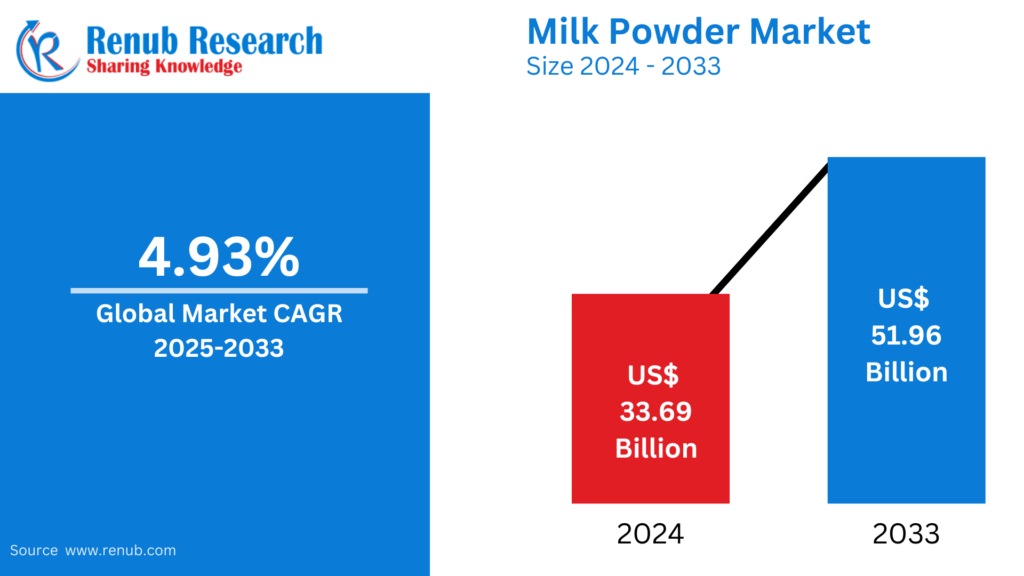
03
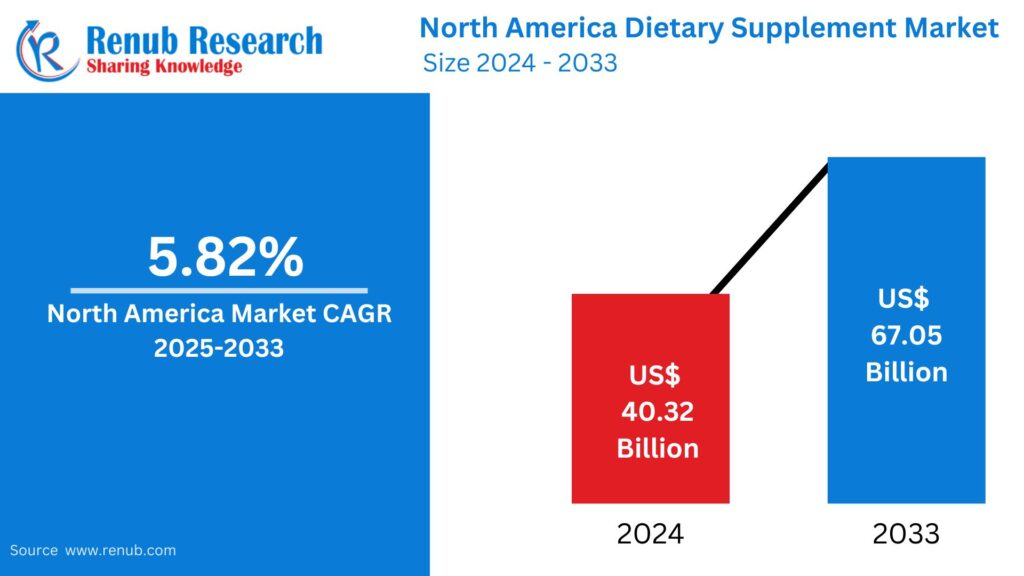
01
03
 04
04
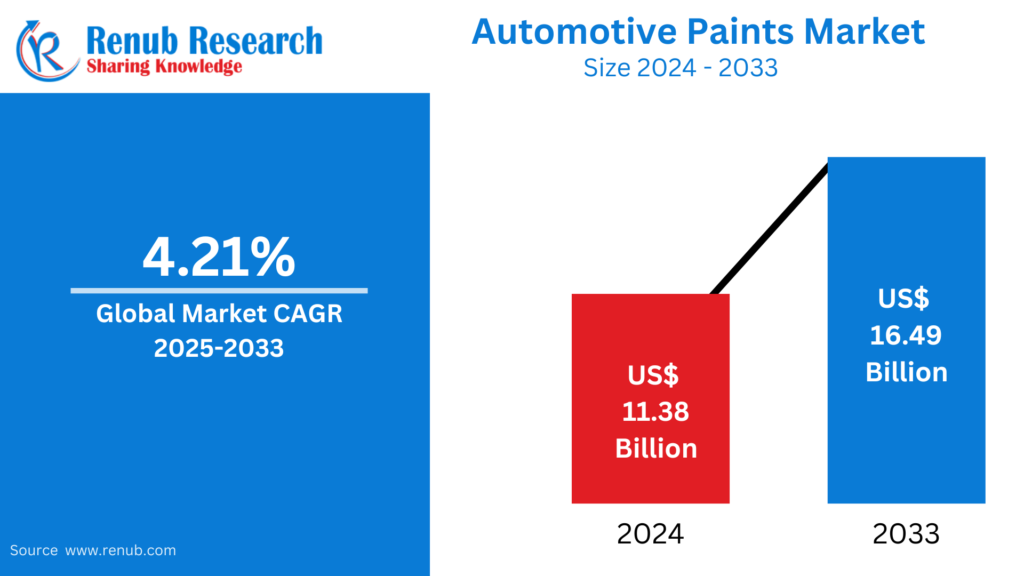
 01
02
03
04
03
01
02
03
04
03
 04
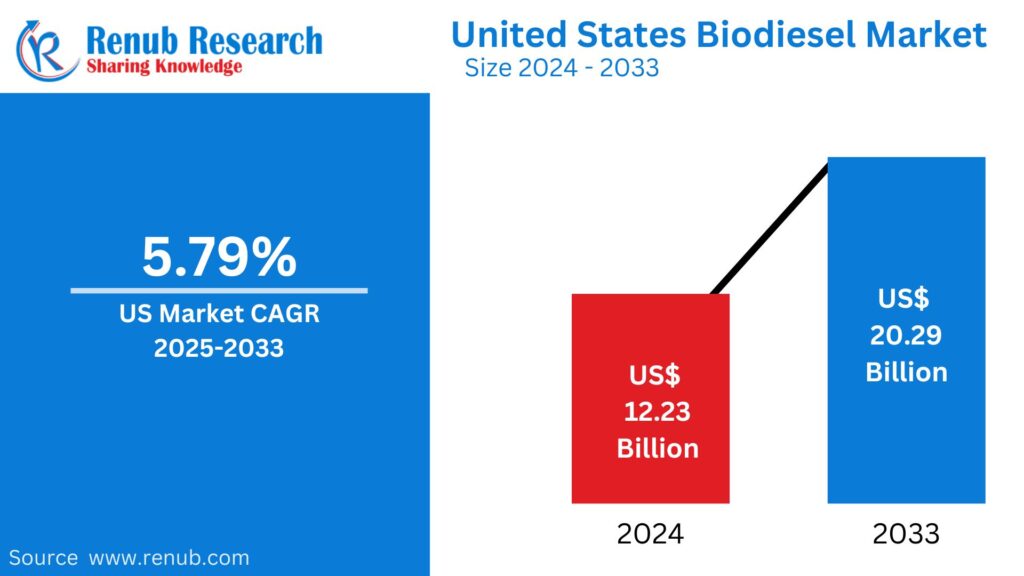
01
02
04
01
02
 03
04
01
02
03
04
03
04
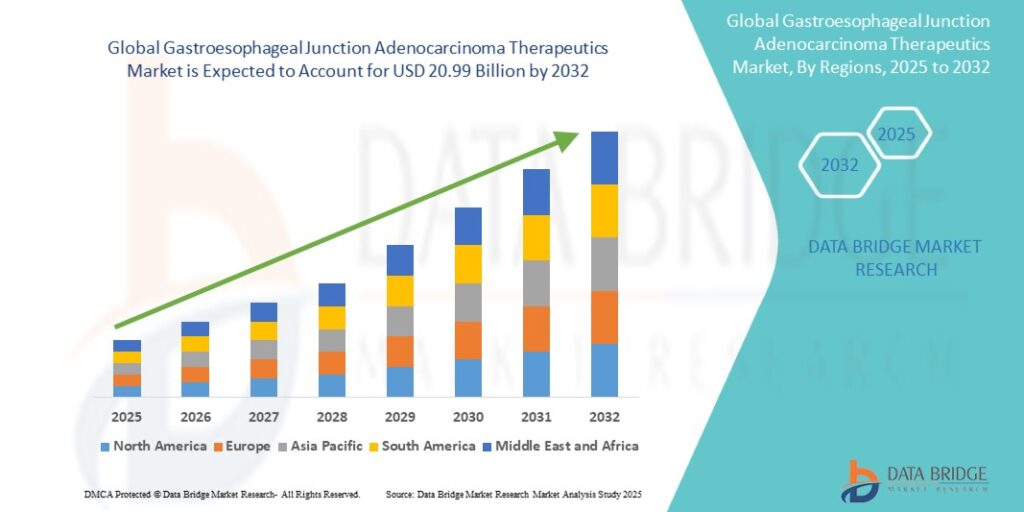
01
02
03
04
01
02
03
04
03
04
01
02
03
04
03
04
01
02
03
04
01
02
03
04
 01
02
03
01
02
03
 04
01
02
03
04
01
02
03
04
01
02
03
04
05
06
01
02
03
04
06
01
02
03
04
05
06
04
01
02
03
04
01
02
03
04
01
02
03
04
05
06
01
02
03
04
06
01
02
03
04
05
06




 03
04
03
04


Commercial enterprises and buildings do generate different types of waste depending on the type of business. Professional commercial rubbish removal is a
Are you thinking about making your home more insulated? There is a compelling reason why spray foam insulation is getting
Garages & basements do not get much thought for home fix-ups. They work, sure—but cool? Not that much. But picture
In an era where most popular games require massive downloads, high-end PCs, and constant updates, Drift Hunters proves that you
In a mobile gaming world saturated with elaborate RPGs, endless runners, and puzzle challenges, Slice Master makes its mark by
In a world where word games have found a renaissance thanks to the viral rise of Wordle, a handful of
In today’s digital financial era, finding the best forex trading platforms is a crucial step for any trader who aims to succeed
Repainting your home might seem like a basic task, but it makes a big difference. A fresh coat of paint—whether
Using the right brushstroke is the first step in transforming the way your space looks and feels. Whether you’re painting
Al giorno d’oggi, quasi tutti noi utilizziamo il computer per lavorare, studiare, fare acquisti o divertirci. Ma cosa succede quando
Introduction: The Importance of Choosing the Best Forex Trading Platforms In today’s fast-paced financial markets, selecting the best forex trading platforms is
Bonding and spending time with their father is important to the overall development of a child. As per Evan Bass
Attracting and retaining top talent in a business is the key to maintaining a competitive edge according to Charles Spinelli.
The first 90 days of working with a financial advisor are as vital for the professional as the client. It’s
Moving to a new home is quite a stressful and time-consuming endeavour. Preparing for a move involves a myriad of


This may be the latest case of post aggression emigration in Ukraine. But it is unlikely to be the final stage for millions of people to leave the country. These people do not want
 English
English